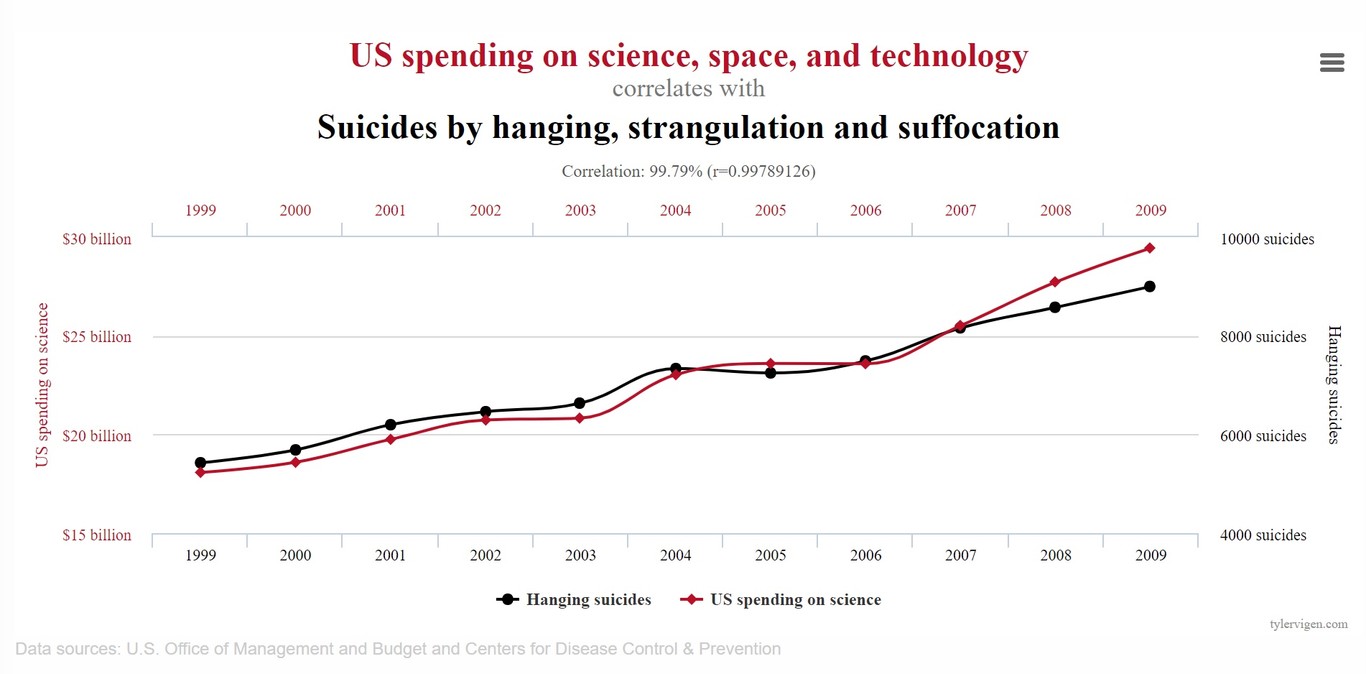
Estos días estoy viendo correlaciones más o menos buenas; más menos que más. Sus coeficientes de correlación son malos, pero sin embargo salen a la calle y nadie les dice nada. Sorprendentemente, resulta que no son malas. Voy a explicar por qué.
Comencemos por el principio. Hay ocasiones en que queremos ver si dos variables (x,y) están correlacionadas. Eso quiere decir que hay alguna relación entre ellas. Puede ser que sí, o puede que sean independientes.
Vamos a restringirnos al caso lineal. Es decir, supongamos que la relación entre x e y es del tipo y=A*x+B, donde A, B son constantes (A es la pendiente, B es la ordenada en el origen). Eso quiere decir que, cada vez que mida un valor de x, obtengo un valor de y que cumpla y=Ax+B. Por lo general se miden distintos valores (x1,y1) (x1,y2)… (xn,yn), y cuando hago una gráfica Y-X (y en el eje vertical, x en el horizontal), los puntos forman una recta perfecta.
Eso en el país de la piruleta.
En el mundo real, una recta perfecta raramente sucede. Hay fallos de medición, problemas con los instrumentos, y además la naturaleza conspira para ofrecernos relaciones complejas, de modo que para obtener y a partir de x no basta con hacer y=A*x+B, sino que hay muchas más cosas que influyen.
Digamos, por ejemplo, que quiero relacionar el número de libros en una casa con la puntuación PISA de los niños que allí viven. Se ha hecho, y los datos son de todo menos una recta. Evidentemente, la calificación escolar depende de muchos más factores que de cuántos libros hay en casa. Aun así, puede que haya una relación entre las variables “libros en casa” y “puntuación PISA”. ¿Cómo obtenerla?
Aquí entra el ajuste. Básicamente significa que, aunque los puntos no formen una recta, sí podemos aproximarlos a una recta. No será una relación ideal, pero más vale eso que nada. Este es un ejemplo típico:

Como veis, la recta de ajuste no pasa por ningún punto en concreto. No tiene por qué hacerlo, ya que es una solución de compromiso. El ajuste lineal nos da A, B junto con sus cotas de error, y a partir de ahí podemos seguir trabajando
Ahora bien, el ajuste lineal no es la panacea. Yo siempre digo que es como un soldado tonto pero obediente. Tú le dices que ajuste y el ajusta. Y eso no siempre va bien, como se puede ver en la siguiente gráfica:
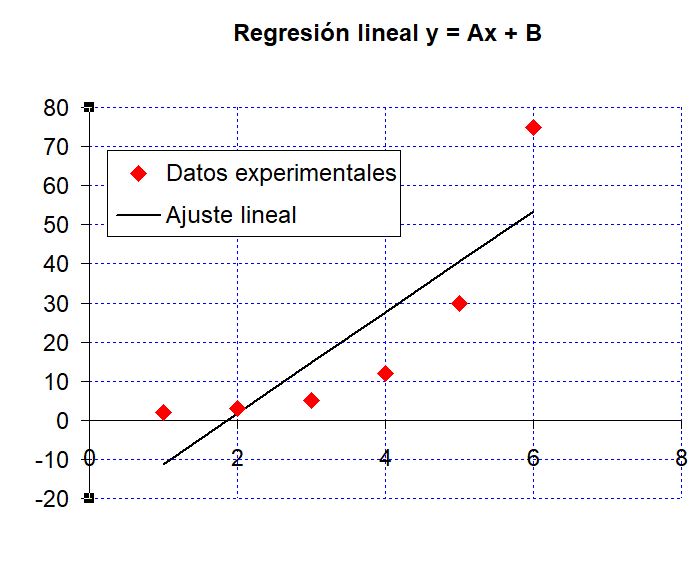
Está claro que los rombos rojos se parecen a una recta como un huevo a una castaña, pero el programa es obediente y ajusta.
Para cuantificar la “rectitud” de los puntos se usa un parámetro llamado coeficiente de correlación lineal (r). El valor de r está entre -1 y +1. Lo importante es el módulo: cuanto más cercano a la unidad, mejor es el ajuste, y │r│=1 es una recta perfecta. En muchos casos se utiliza R2, que para un ajuste lineal no es más que el cuadrado de r. Eso nos quita el engorro del signo, y si el módulo de r se acerca a uno, R2 también.
Ahora viene la pregunta clave: ¿cuánto tiene que valer r (o, lo que es equivalente, R2) para que el ajuste sea considerado bueno? Hay muchos textos y guiones de prácticas donde dan valores aproximados y fijos, del tipo “si │r│>0,95 vamos bien, si es mayor que 0,85 es aceptable, si no es malo”. Yo mismo he usado criterios similares para mis alumnos durante muchos años.
Resulta que la verdad es más complicada que eso.
En general, podemos tener un conjunto de puntos que no estén correlacionados pero, por casualidad, tienden a formar una recta. Podéis verlo en una diana. Tirad cinco veces el dardo y los puntos de impacto estarán más o menos al azar. Tiradlos cien veces, y raro será que no formen algún tipo de patrón.
Eso nos dice dos cosas. Primero, que podemos tener un buen ajuste por puro azar, sin que haya correlación alguna; segundo, que la bondad del ajuste depende del número de datos.
Si no sabíais eso, no os preocupéis. Soy profesor universitario de Física desde hace casi treinta años, doy prácticas de laboratorio todos los años, y nunca me explicó nadie este problema. Sólo hace un par de años encontré un comentario al respecto en un excelente libro que me prestó un compañero (“Introducción al análisis de errores” de John R. Taylor, por si os interesa).
La idea es la siguiente. Cuando tenemos un conjunto de puntos, puede que estén alineados porque están correlacionadas las variables (x,y), o puede que lo hagan por casualidad. La buena noticia es que podemos establecer cualitativamente si ese es el caso; es decir, podemos saber la probabilidad de que un conjunto de N puntos, que dan un coeficiente de correlación r (voy a olvidarme del módulo, no es necesario ahora), estén colocados al azar o no.
Esa es, como digo, la buena noticia. La mala noticia es que los cálculos no son sencillos. Incluso en el libro de Taylor (que es muy bueno) hay poca información sobre cómo se hace el cálculo. Apenas lo justo. La ecuación que nos da la información es una integral, incluye funciones gamma… ¡y tiene erratas! ¿Cómo lo sé? Pues porque Taylor da una referencia de un libro… de 1966. Felizmente pude encontrarlo, leer y aprender. Incluso pude reproducir los datos en una hoja de cálculo.
En Taylor y otros libros, la información viene en forma de tabla. Tomas el número de puntos N, el coeficiente de correlación que te ha salido, y la tabla te da la probabilidad de que ese ajuste se deba al azar.
Vamos a usar un ejemplo. Hace unos días la AEMET y el Instituto de Salud Carlos III publicaron una correlación entre la temperatura ambiente y la prevalencia de casos de coronavirus. Este fue el resultado para el 26 de marzo:

Se trata de un ajuste exponencial, pero si convertimos IA (índice acumulado de casos) en su logaritmo obtenemos una relación lineal (más información sobre la conversión de exponencial a recta en este post).

Los datos de esta gráfica son: Log (IA) = 7,4257 -0,2663*T
¿Cuánto vale el coeficiente de correlación para esta recta? Los chicos de la AEMET/ISCIII nos dan un valor de R2=0,5245, o lo que es lo mismo, r=0,724.
Supuestamente un valor de r tan pequeño sería inaceptable, pero esa gente son profesionales. ¿No se habrán dado cuenta de eso? Aparentemente no, pero eso olvida el factor del número de puntos.
Si tuviésemos cuatro puntos, la probabilidad de que la correlación fuese fruto del azar sería del 28%, demasiado alta para poder declarar victoria. Ahora bien, para N=17 la probabilidad de que la correlación sea fruto del azar es del 0,1%. Dicho de otro modo, la probabilidad de que esos 17 puntos se alineen de esa forma y SÍ estén correlacionados es del 99,9%
Así que ese ajuste es matemáticamente correcto.
Aun así, tengo mis reservas.
En primer lugar, podemos saber si el ajuste es bueno o no, pero eso no nos garantiza que los puntos realmente formen una recta. Fijaos en el siguiente ejemplo:

Es un ajuste estadísticamente significativo. Tiene un valor de r=0,974, lo que consideraríamos bueno. La tabla nos da la probabilidad de que esta correlación sea fruto del azar, y en este caso es del 0,1%. Justo que antes, la probabilidad de tener una correlación es del 99,9%. Pero el ojo ve enseguida que esos puntos parecen formar una curva. Y así es. Forma una parábola perfecta y=x2. Aquí la estadística juega a Groucho Marx y nos pregunta eso de “¿a quién va usted a creer, a mí o a sus propios ojos?” Pues amigo Groucho, lo siento pero eso no es una recta.
Hubo un problema adicional con el ajuste de AEMET/ISCIII, y es el de siempre: correlación no implica causalidad (más sobre el tema aquí, aquí y aquí; bueno, y también aquí, pero eso ya cuesta moneda). Incluso admitiendo que sus datos estén correlacionados (y, como acabamos de ver, lo están al 99,9%), eso no implica que la temperatura sea la causa y la incidencia en casos de coronavirus la consecuencia. Tanto es así, que lo primero que hice es pensar en la famosa gráfica de la temperatura y los piratas:

El problema es que los datos de la AEMET/ISCIII rápidamente malinterpretados por los medios de comunicación, quienes rápidamente convirtieron la correlación en una causalidad. “La temperatura influye en el número de casos”, afirmaban. De ahí a predecir que en verano vamos a tener muchos menos casos y que ya va siendo hora de acabar con el confinamiento no hay más que un paso.
La AEMET y el ISCIII tienen parte de responsabilidad en ello. Aun cuando intentaron dejar claro que correlación no implica causalidad (y el título hablaba prudentemente de “primeros indicios de correlación”), el mero hecho de hacer una gráfica ya implica que el eje de abscisas contiene la causa y el de ordenadas, la consecuencia, porque eso es lo que es habitual. Poner “incidencia de casos vs temperatura” ya deja claro la cosa. Peor aún, en el texto hablan textualmente de “a menor temperatura promedio, mayor incidencia”, dejando claro qué consideran causa y qué efecto. Mala elección de palabras en mi opinión.
(Por cierto, si queréis ver un montón de correlaciones absurdas, os recomiendo esta página. Entrad y disfrutad)
Puede que la relación causa-efecto no exista. Puede que haya un tercer factor involucrado, como el simple paso del tiempo (se me ocurren muchas explicaciones). Y fijaos en la sensibilidad de los datos a los puntos extremos: si quitamos La Rioja y Canarias, r baja del 0,724 a 0,582, y ahora la probabilidad de que no haya correlación salta del 0,1% al 2,3%.
Finalmente, el ejemplo de la parábola nos indica que un buen ajuste lineal es sólo eso, un buen ajuste lineal, pero no nos justifica que ese sea el mejor ajuste posible. ¿Por qué lineal y no cuadrático o polinómico? Eso conlleva el riesgo de ponerse a hacer ajustes de todo tipo, en la esperanza de que alguno vaya bien.
Un ejemplo de esto es una gráfica que me encontré ayer mismo por Twitter:
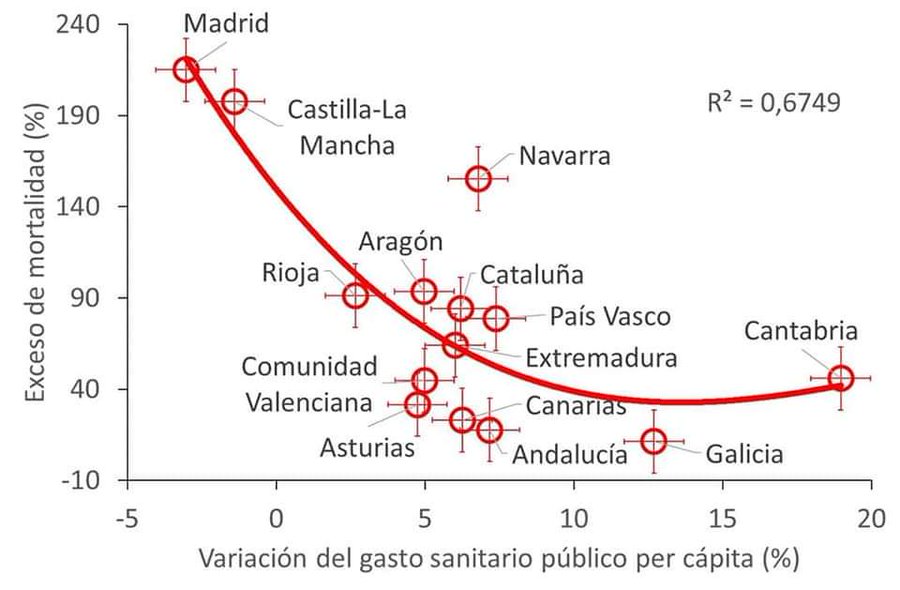
(Imagen original: @MaximoFlorin, retuiteado por Alberto Nájera)
Tengo muchas pegas que ponerle a esa gráfica, pero centrémonos en los datos del ajuste solamente. R cuadrado vale 0,6749, r=0,822, probabilidad de correlación por puro azar… 0,03%. Fabuloso según la estadística. Pero enseguida me pregunté qué curva es esa y por qué se escogió. Recibí respuesta a la primera pregunta (es del tipo y3), no a la segunda. Si es la curva que mejor ajusta, vale, pero no tiene sentido. Pensadlo un poco. ¿Realmente tiene sentido? Según esa curva, para variación de gasto superior al 10-15% la mortalidad aumenta. ¿Tiene sentido eso?
Aquí hay algo que falla. Estamos rodeados de gráficas con muchos puntos y ajustes matemáticamente válidos, y automáticamente las damos como buenas. No deberíamos. La estadística es una herramienta que nos ayuda en la toma de decisiones, pero no son un pozo de sabiduría en sí mismo. Creo que fue Mark Twain quien dijo “los datos son como las personas, tortúralos lo bastante y te dirán lo que quieras”. O a lo mejor fue Paulo Coelho. No, a ese lo veo menos probable. Pero no hay test para eso.
Arturo,
Agradezco que tengas abiertos los comentarios. Aprovecho para hacer un pequeño inciso sobre una de las cuestiones que tocas con el único propósito de ofrecer una luz distinta.
Es curioso cómo el hecho de que cada uno lleguemos a los conceptos desde nuestro campo de conocimiento puede afectar en cierta medida a la forma de ver lo mismo. No quiero extenderme mucho pero me hace cierta gracia el hecho de que un R² de 0,52 te parezca bajo hasta resultar inaceptable. Probablemente lo es en un contexto de laboratorio pero ni mucho menos lo es en otros. Vaya por delante que probablemente el R² sea uno de los peores criterios existentes a la hora de evaluar la bondad de un modelo y que en muchas ocasiones es mejor sencillamente ignorarlo. Una de las propiedades de R² es que es eso, como bien dices, el cuadrado del coeficiente de correlación lineal r entre los valores de la variable dependiente y los variables predichos de la misma y que en el caso de una única variable independiente coincide con el coeficiente de correlación entre la variable dependiente y la independiente. Pero tiene también otro significado: es la proporción de la variabilidad (varianza) de la variable independiente explicada por la regresión. Que una sola variable, la temperatura, en un modelo tan sencillo explique un 52% de la varianza en el exceso de mortalidad no me parece poco: ¡me parece una barbaridad! ¿Qué porcentaje dejamos a la densidad de población, estratos demográficos, número de camas o médicos por habitante, etc.? Por supuesto tienes razón: podría ser una correlación espúrea o puede que la variable relevante esté correlacionada con la temperatura pero no sea ésta (por ejemplo hacer más vida en la calle y menos en espacios cerrados con mucha gente).
Y lo dejo ahí, como decía antes, con el único propósito de arrojar una luz distinta sobre lo bueno o lo malo que es un R² de 0,52 😉
Un abrazo
Excelente analisis! quedé con un panorama muy amplio con tu manera de explicarlo. Muchas gracias por tu aporte. Saludos desde México
Gracias, Jonathan, por tus palabras. Me alegra que te haya sido útil. Saludos. AQ